在前幾天的學習中,我們深入了解了生成式模型中的自編碼器(Autoencoder)和變分自編碼器(VAE),它們在學習數據分佈和生成新數據方面的應用。今天,我們將探討另一種強大的生成式模型——生成對抗網絡(Generative Adversarial Networks,GAN)。GAN在圖像生成、圖像轉換和數據增強等領域取得了令人矚目的成果,也是實現AI換臉技術的核心模型之一。
生成對抗網絡由Ian Goodfellow等人在2014年提出,是一種新穎的生成式模型。GAN通過生成器(Generator)和判別器(Discriminator) 之間的對抗訓練,能夠學習數據的真實分佈,並生成逼真的新數據。
GAN的核心思想是將生成問題轉化為一個雙人零和博弈:
兩者在訓練過程中相互對抗,最終達到一個納什均衡,生成器能夠生成以假亂真的數據。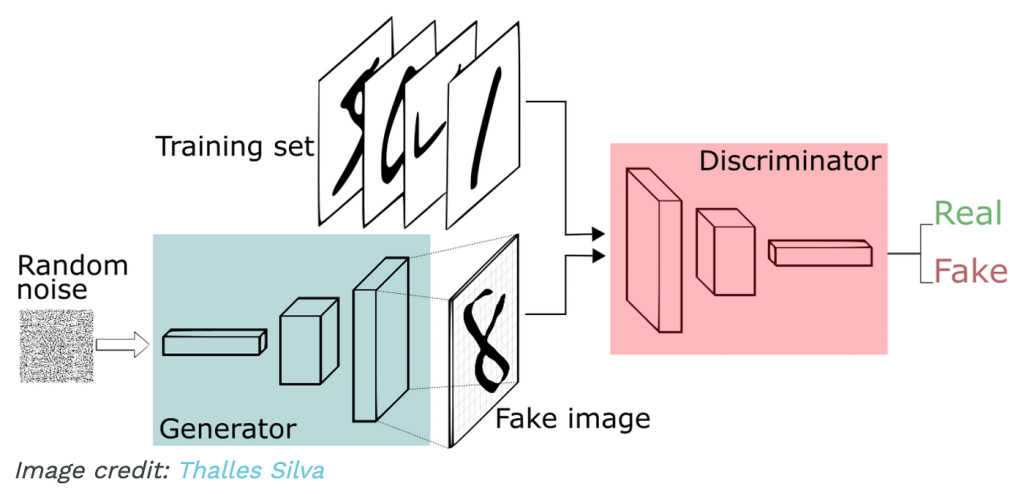
圖1 生成器和判別器之間的對抗關係。
GAN的目標是解決一個極小極大問題,其目標函數為: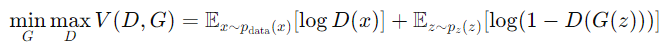
今天我們深入探討了生成對抗網絡(GAN)的原理、結構和應用。GAN通過生成器和判別器之間的對抗訓練,能夠生成逼真的數據,在圖像生成和換臉技術中具有廣泛的應用。雖然GAN的訓練存在挑戰,但隨著技術的不斷發展,各種改進的模型和方法正在不斷涌現。在接下來的課程中,我們將學習如何實際構建和訓練GAN模型,並將其應用於AI換臉項目中。
那我們就明天見了~ 掰掰~~

